RAG-检索增强生成
欢迎来到以DeepSeek以代表的AI世界,我是doc-war.com的青樵,一个技术主义者。
知行合一,继续用DeepSeek写DeepSeek教程。
推荐提问
- 请详细介绍下RAG(Retrieval-Augmented Generation,检索增强生成)
- 请详细解读下TAGflow这个平台,并阐述其最大的挑战
一、RAG位置
与Agent创业不同,RAG代表了一个反向的思维,他处在LLM权重数据集的平层。RAG通过实时检索外部知识,为DeepSeek这样的LLM生成提供最新、可靠的上下文。
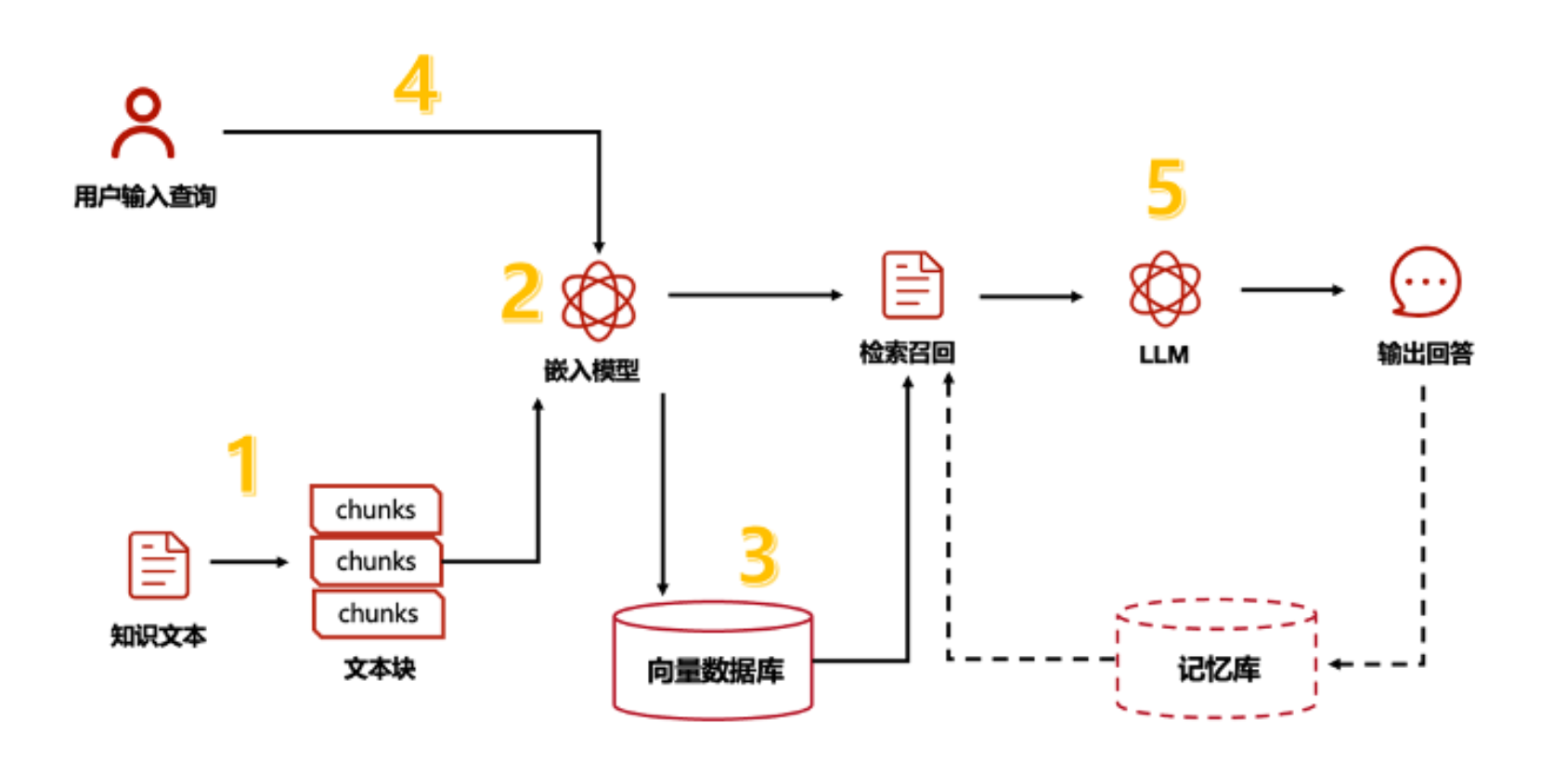
第一性原理
他解决一个什么问题呢?
传统生成模型(如GPT)仅依赖训练数据,易产生“过期幻觉”。
什么意思呢,从数据的生命周期来看,LLM先将素材消费掉,形成权重数据,再基于权重数据推理,生成结果。但对于一些领域性的、业务性的、企业级的、并且可能还在持续修正的数据,这个代价是有点大的,因为要进入LLM的核心价值的生命周期之内,我们已经很清楚的知道,LLM训练极度费钱。
于是,聪明的人想到了一个方案,这部分数据我能否外挂,推理时根据检索规则来实时获取?
这就是RAG——检索增强生成!
所以, RAG 的本质:LLM 数据生命周期的“外挂式扩展”。
关键价值
RAG 的实际意义:企业级数据与 LLM 的“低成本融合”
- 避免重复训练:企业无需将业务数据“喂给”LLM 重新训练,节省算力与时间成本。
- 数据主权保留:敏感数据(如企业内部文档)始终可控,不进入模型黑箱。
这里涉及了传统痛点
企业若想将内部数据(如产品文档、客服记录)融入 LLM,需经历:
- →数据清洗
- → 微调训练
- →部署验证
- →持续迭代(循环)
成本高、周期长,且无法适应高频数据更新(如政策法规变化)。
刚需
RAG 带来的特性:
- 即插即用:将企业数据构建为向量化知识库,与 LLM 解耦。顺带还能突破LLM的上下文长度限制。
- 实时生效:知识库更新后,LLM 下次推理立即感知新内容。
- 可控性强:可针对不同场景配置不同知识库(如分部门、分产品线)。
典型刚需场景
- 法律咨询:RAG 接入最新法律条文库,确保生成结果符合时效性要求。
- 电商客服:产品信息变更后,无需重新训练模型,直接更新知识库即可。
- 内容生成:辅助撰写报告、文章时自动检索并引用权威数据,确保内容可信。
- 数据分析:从非结构化数据(如会议记录)中提取信息,生成结构化摘要或图表。
二、RAGflow方案
由于RAG是一个AI领域的通用业务概念,很显然没必要每一家企业都重复造轮子,所以这个领域诞生了多种RAG解决方案。其中包括RAGflow,他既是一个开源框架,也是一个平台。
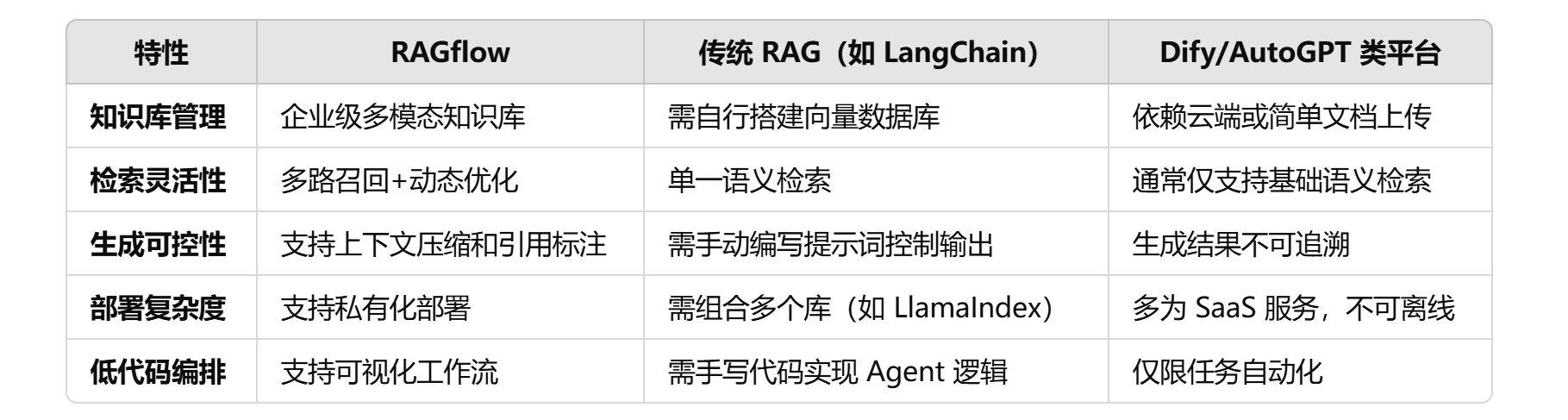
我们可以借助RAGflow来更好的理解RAG。
RAGflow 的核心设计
RAGflow 通常通过以下技术优化传统 RAG 流程,形成端到端的解决方案:
模块化架构
RAGflow 典型架构:
|-- 数据预处理模块
|-- 文档解析(PDF/Word/HTML 等)
|-- 文本分块与向量化
|-- 知识库存储(向量数据库,如 FAISS、Milvus)
|-- 检索模块
|-- 多路召回(语义检索+关键词检索)
|-- 重排序(基于相关性评分)
|-- 生成模块
|-- 上下文压缩(提取关键片段)
|-- 大模型提示工程(如 GPT、Llama)
|-- 结果后处理(引用标注、格式优化)关键创新点
- 动态检索优化: 支持实时更新知识库,结合用户反馈动态调整检索策略(如调整权重或召回阈值)。
- 多模态支持: 可处理文本、表格、图像混合内容(如解析 PDF 中的图表并关联文本)。
- 可解释性: 生成的回答附带引用来源(如标注具体文档段落),提升可信度。
- 这种设计降低了开发门槛,使技术专家和业务人员都能快速构建和部署 AI 应用
功能特点
企业级功能
- 权限管控:支持基于角色的知识库访问控制。
- 审计日志:记录检索和生成过程,满足合规要求。
- 多租户支持:为不同团队或客户隔离数据和流程。
开发者友好
- API 接口:提供 RESTful API 或 SDK,便于集成到现有系统。
- 可视化界面:内置管理后台,支持非技术人员上传文档、配置检索规则。
- 自定义扩展:允许替换检索模型(如从 BM25 切换到 ColBERT)或生成模型。
三、RAG诅咒
RAGflow虽好,但架不住天生缺陷,从第一性原理来说,RAG有未来,但RAGflow却没有光。
最大的问题,目前的RAG技术是一种介于传统数据处理架构和AI机制之间的中间型态产物。
——构建高质量知识库涉及文档切片、向量化策略,需要AI领域经验,相当于LLM厂商干的一部分活落到了你头上:
- 对于小型企业,这是巨大的专业门槛。
- 这非常的不符合AI时代的高效理念。
比如一本1000页的图书,你需要切成5000个碎片粒度来存储,怎么切本身就是对人的巨大要求,更何况工作量。如果我希望将Deepseek教程网用RAG技术来处理,这绝对不亚于从零创建这个内容网站的过程。而基于第一性原理,最佳的解决方案是:用AI来实现RAG,最终反过来解决AI的问题。
而这,就是RAG的宿命